
The Ugly Side Of Deepseek

본문
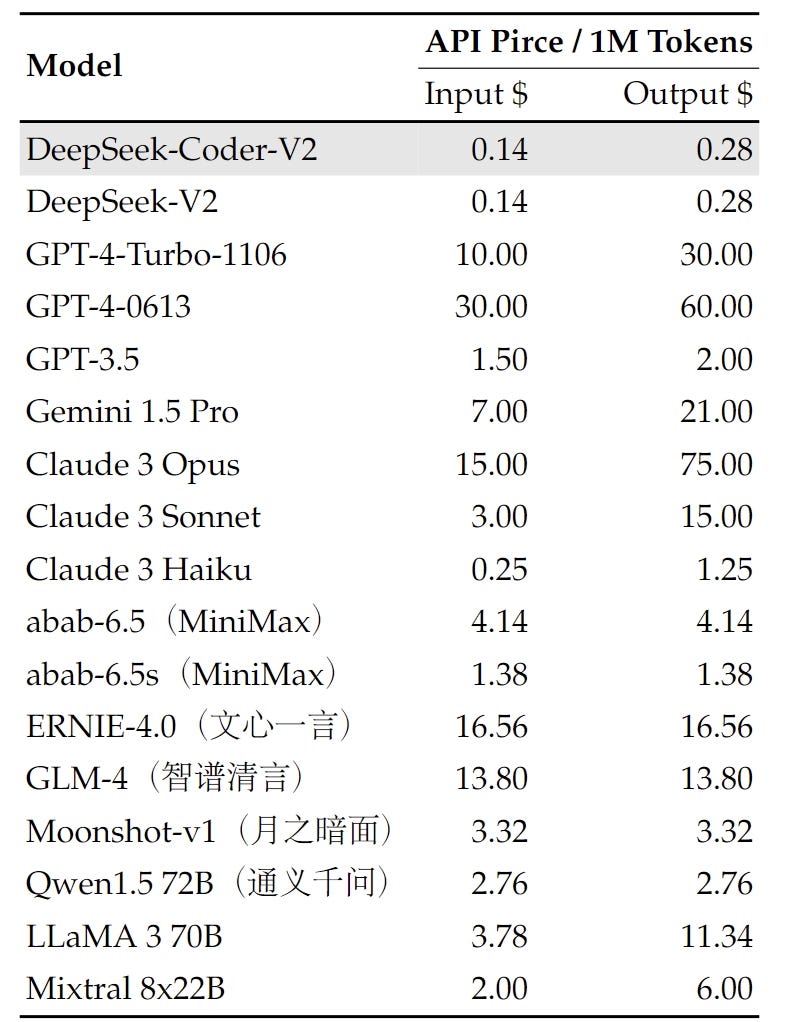 The DeepSeek v3 paper (and are out, after yesterday's mysterious launch of Loads of interesting particulars in right here. Loads of fascinating details in here. Figure 2 illustrates the fundamental architecture of DeepSeek-V3, and we will briefly assessment the main points of MLA and DeepSeekMoE on this section. This is a visitor put up from Ty Dunn, Co-founding father of Continue, that covers the way to arrange, explore, and work out one of the best ways to use Continue and Ollama together. Exploring Code LLMs - Instruction high-quality-tuning, models and quantization 2024-04-14 Introduction The goal of this publish is to deep-dive into LLM’s that are specialised in code generation duties, and see if we are able to use them to write code. 2024-04-15 Introduction The goal of this submit is to deep-dive into LLMs that are specialised in code technology tasks and see if we will use them to write down code. Continue enables you to simply create your personal coding assistant straight inside Visual Studio Code and JetBrains with open-supply LLMs. 2024-04-30 Introduction In my previous submit, I tested a coding LLM on its means to write React code. Paper summary: 1.3B to 33B LLMs on 1/2T code tokens (87 langs) w/ FiM and 16K seqlen. V3.pdf (by way of) The DeepSeek v3 paper (and model card) are out, after yesterday's mysterious release of the undocumented mannequin weights.
The DeepSeek v3 paper (and are out, after yesterday's mysterious launch of Loads of interesting particulars in right here. Loads of fascinating details in here. Figure 2 illustrates the fundamental architecture of DeepSeek-V3, and we will briefly assessment the main points of MLA and DeepSeekMoE on this section. This is a visitor put up from Ty Dunn, Co-founding father of Continue, that covers the way to arrange, explore, and work out one of the best ways to use Continue and Ollama together. Exploring Code LLMs - Instruction high-quality-tuning, models and quantization 2024-04-14 Introduction The goal of this publish is to deep-dive into LLM’s that are specialised in code generation duties, and see if we are able to use them to write code. 2024-04-15 Introduction The goal of this submit is to deep-dive into LLMs that are specialised in code technology tasks and see if we will use them to write down code. Continue enables you to simply create your personal coding assistant straight inside Visual Studio Code and JetBrains with open-supply LLMs. 2024-04-30 Introduction In my previous submit, I tested a coding LLM on its means to write React code. Paper summary: 1.3B to 33B LLMs on 1/2T code tokens (87 langs) w/ FiM and 16K seqlen. V3.pdf (by way of) The DeepSeek v3 paper (and model card) are out, after yesterday's mysterious release of the undocumented mannequin weights.
The paper attributes the robust mathematical reasoning capabilities of DeepSeekMath 7B to 2 key elements: the extensive math-associated knowledge used for pre-training and the introduction of the GRPO optimization approach. Getting Things Done with LogSeq 2024-02-16 Introduction I was first launched to the concept of “second-mind” from Tobi Lutke, the founding father of Shopify. Specifically, DeepSeek launched Multi Latent Attention designed for environment friendly inference with KV-cache compression. KV cache during inference, thus boosting the inference efficiency". • Managing fantastic-grained memory layout during chunked data transferring to multiple specialists throughout the IB and NVLink domain. However, Vite has reminiscence usage issues in manufacturing builds that may clog CI/CD programs. Each submitted solution was allotted either a P100 GPU or 2xT4 GPUs, with up to 9 hours to unravel the 50 problems. DeepSeek v3 educated on 2,788,000 H800 GPU hours at an estimated price of $5,576,000. The industry is also taking the corporate at its word that the cost was so low. By far probably the most interesting detail although is how a lot the training cost.
It’s not simply the coaching set that’s massive. About DeepSeek: DeepSeek makes some extremely good massive language fashions and has also printed a couple of clever concepts for additional enhancing how it approaches AI training. Last Updated 01 Dec, 2023 min learn In a recent improvement, the DeepSeek LLM has emerged as a formidable drive in the realm of language fashions, boasting a powerful 67 billion parameters. Large Language Models are undoubtedly the largest half of the present AI wave and is currently the realm the place most research and investment is going towards. While we've got seen attempts to introduce new architectures equivalent to Mamba and extra not too long ago xLSTM to only title a couple of, it appears doubtless that the decoder-solely transformer is right here to stay - at least for probably the most part. In each text and picture technology, we've seen large step-function like enhancements in model capabilities across the board. This year we've seen important improvements on the frontier in capabilities in addition to a model new scaling paradigm.
A year that started with OpenAI dominance is now ending with Anthropic’s Claude being my used LLM and the introduction of a number of labs that are all attempting to push the frontier from xAI to Chinese labs like DeepSeek and Qwen. A commentator started talking. The subject began because somebody asked whether he still codes - now that he's a founding father of such a large firm. It hasn’t yet proven it could possibly handle a few of the massively bold AI capabilities for industries that - for now - nonetheless require great infrastructure investments. That famous, there are three components still in Nvidia’s favor. Read extra: Diffusion Models Are Real-Time Game Engines (arXiv). Read extra: Learning Robot Soccer from Egocentric Vision with deep seek Reinforcement Learning (arXiv). Following this, we conduct publish-coaching, together with Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the bottom model of DeepSeek-V3, to align it with human preferences and additional unlock its potential. Assuming you've a chat mannequin set up already (e.g. Codestral, Llama 3), you can keep this whole experience native due to embeddings with Ollama and LanceDB. However, with 22B parameters and a non-production license, it requires fairly a bit of VRAM and can solely be used for analysis and testing functions, so it may not be the perfect fit for daily local usage.
댓글목록0
댓글 포인트 안내